
Last week, I talked at an AI Symposium at Millersville University. I chose to explore some new connections of ideas. Below is an AI-generated (which I edited) version of the argument of that talk–here is a Gamma document with images, simulations, etc.
For as long as people have read anything, how well it was written was a clue. A fluent, well-organized explanation usually meant someone who knew the subject stood behind the words, because sounding that way was expensive—it took knowledge, effort, and a real person who’d done the work. We learned to relax our guard a when something read as competent and confident. That instinct served us well….until it didn’t.
Generative AI severs that clue. It can produce confident, authoritative-sounding text on demand and limited cost to the consumer. The signals we have learned to trust come unhooked from the thing that used to make them trustworthy. This talk is about what that means for educators, and about the one resource that doesn’t come unhooked: you.
The whole thing runs on one idea: the most likely
You don’t need much math to follow this, just one sixth-grade word: mode, the most common value in a set. That’s essentially what a large language model does (I am purposefully simplifying here to keep it simple). It predicts the most likely next word, over and over, and scaled up that becomes the most likely response. Useful, often. But “most likely” turns out to hide two problems: one in what the model says, and one in how it sounds.
What it says: “most likely” was never neutral
A few years ago, Planet Money went looking for the most statistically typical American, the “modal” American. The single most common profile turned out to be white, married, and male. Not because that’s the average person, but because that’s the most frequent single type. “Most likely” is the dominant default. (Claude and I made a fun simulation of this where you can see it with 2025 data!)
That matters when a model fills in what it doesn’t know. Because here’s the thing: when an AI lacks information, it doesn’t leave a blank. It can’t. It has to put something down, so it puts down the most likely case: the stereotype.
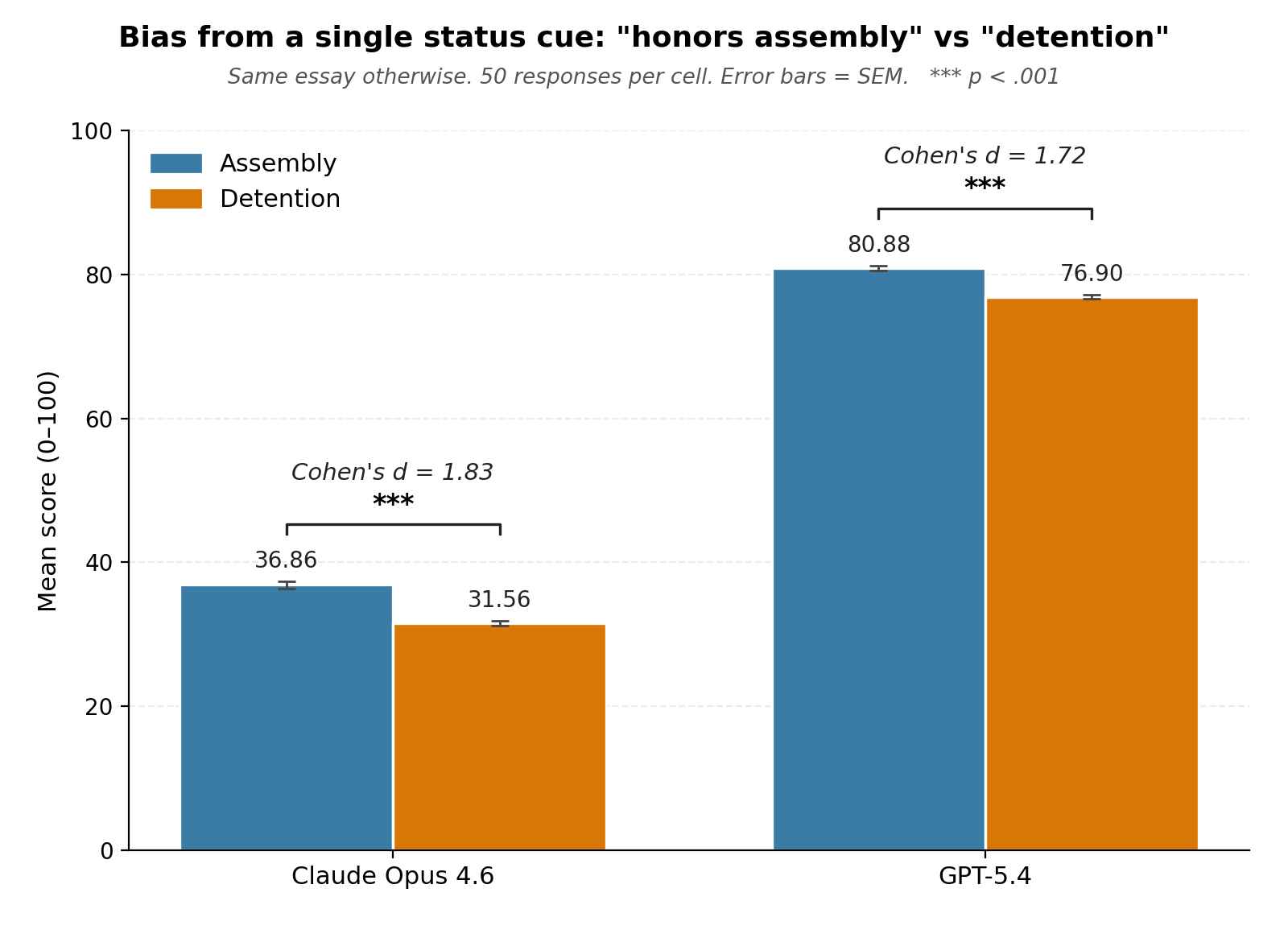
I’ve seen this directly in studies of AI grading. Take one student passage, change a single detail and otherwise leave the essay identical. The scores often move, substantially, and in the same direction across different AI models. The same pattern shows up in how the feedback is written, too: how difficult, how direct, how encouraging. The model isn’t just assigning a number. It’s deciding how to communicate feedback to the student.
The most recent experiment I’ve done found significant results in the newest models when a student-written passage mentioned attending an honors assembly vs. attending detention.
“But it personalizes for me,” you might think. “I tell it my context and it adjusts.” It does, but personalization doesn’t escape the most-likely problem; it just makes it conditional. Tell the model you’re a rural ESL teacher and it stops giving you the most likely American and starts giving you the most likely rural ESL teacher — the stereotype of your group, dressed up as something made just for you. It’s like an adjustable seat that looks bespoke but only clicks into a handful of preset positions. The seat moves. It still doesn’t fully fit you.
How it sounds: honest non-signals
Even when the content is skewed, why don’t we catch it? Because it arrives sounding so credible we don’t think to question it.
The researcher Andrew Maynard has a useful phrase for this: “honest non-signals.” The cues are honest in that the AI isn’t faking them: the fluency is real, the confidence is real, even the apologies are real. But they’re non-signals because they no longer carry the information their human versions would. In a person, fluency points to organized knowledge and an apology costs something, which is exactly why we believe it. In a model, both are free. The signal is there; the structure that made it mean something is not.
Think of any response as the tip of an iceberg. When a knowledgeable human says something fluent, the visible tip rests on a huge submerged mass — their experience, their training, their stake in being right. We never actually see that mass; we infer it from the tip, and for all of human history that inference was safe.
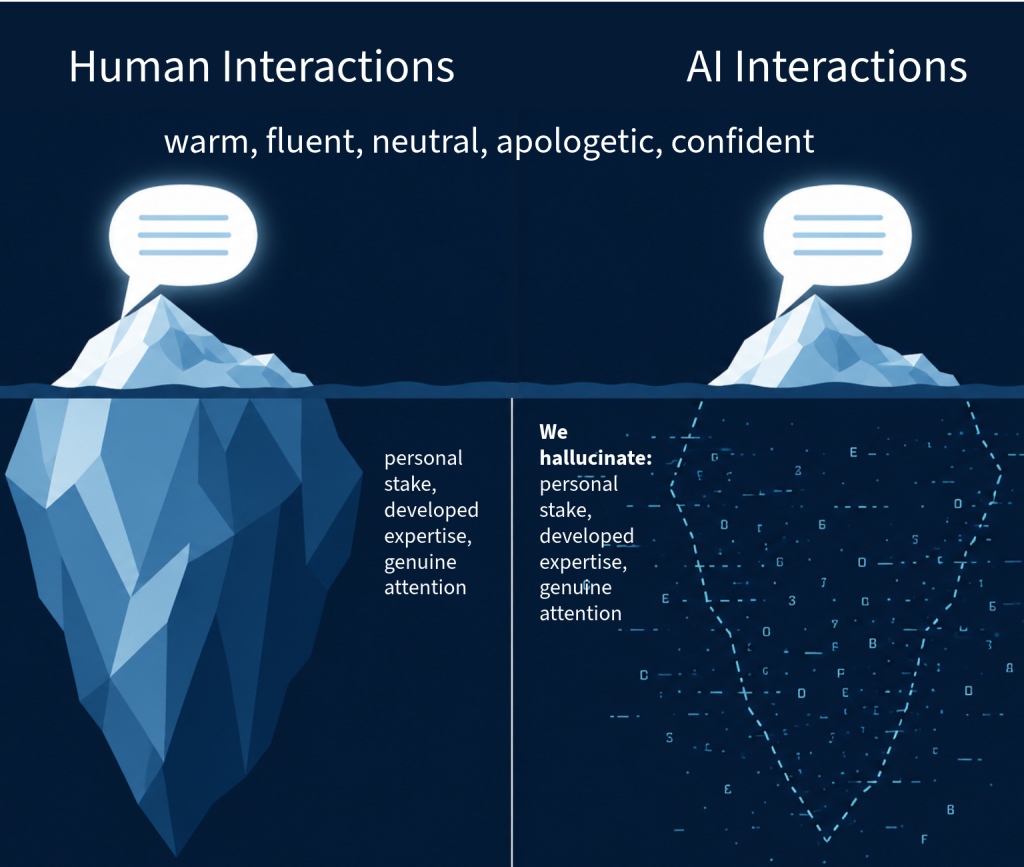
Two icebergs, identical above the water.
AI hands you the tip with an artificial mountain beneath it. Your mind does what it has always done: it fills in the depth that isn’t there. We hallucinate the foundation behind the response. That’s the real danger—not that we fail to check, but that we automatically supply a credibility the words haven’t earned. (It’s not even that there’s nothing underneath; there is something—but it’s a vast statistical machine for the most-likely word, not a mind that knows. The base is made of the wrong stuff.)
And knowing it’s a machine doesn’t protect us. If anything, the most confident, fluent readers are the most exposed, because a tool that articulates what we already believe is the hardest thing to argue with.
So you become the standard
Here’s the turn. When how it sounds stops being a reliable guide, the standard has to become the one you bring. “You” three parts:
- What you’ve lived. Your experience tells you what’s missing or wrong — that’s not how it actually works where I teach. This is the lens that catches the stereotype the model filled in.
- What you’ve learned. Your expertise and reasoning tell you what’s valid — whether the logic holds, whether the evidence supports it, whether it fits what your field knows.
- The limits of both. This is the part almost no one talks about, and it’s the most important. Knowing your own standard means knowing how far it actually reaches: where you’re out of your depth, and where to be skeptical of your own reaction — especially when the AI flatters what you already think. The people most at risk aren’t the ones who know nothing. They’re the confident.
That last piece keeps the first two honest. The standard you bring is only as good as your honesty about where it ends. Self-skepticism here isn’t weakness; it’s what makes your judgment trustworthy rather than just loud.
Look back at the iceberg. The solid mass under the human tip — the stake, the expertise, the genuine attention — that’s you. It’s the thing the machine is only pretending to have. Which is why the answer to a tool that gives you the most likely is not a better tool. It’s a more present person.
Where this starts in practice
None of this means rejecting AI. It means reading it against something. You can’t read AI critically with nothing to compare it to, so the first move is simple: before you accept what it gives you, set your own world beside it, including acknowledging your own limitations and whether you have the skills to truly evaluate it. What does the AI leave out? Who does its “most likely” erase? Where does your lived knowledge say not quite? That habit — noticing what’s missing by holding it up against what you actually know, and being honest with what you don’t know — is the beginning, and it’s a skill worth practicing on purpose.
The machine gives you the most likely. You bring everything “most likely” leaves out. In a world of fluent, confident, authorless text, that turns out to be the rarest and most valuable thing in the room.
Sources and further reading: Andrew Maynard, “Honest Non-Signals, Constitutive Resonance, and Human-AI Interaction.” Planet Money, “The Modal American.” Punya Mishra on the expertise paradox. Grading-bias figures are from my own studies.