
Note: Cover image (including embedded racial bias) from Dall-E 3 via ChatGPT4.0
I’ve been doing some random tests with ChatGPT and other large-language models (LLMs) (some perhaps a bit more meaningful than last week’s Benford’s Law…). Today’s exploration:
If I tell ChatGPT that something is written by a student who likes rap music–vs classical music–will it give the said student different scores on the same writing passage?
Spoiler: the answer is yes–why else would I be writing this? But a bit of background.
Last September I discovered some clear bias in ChatGPT. Basically, I gave ChatGPT a description of a student–such as:
“This passage was written by a 7th grade student from a Black family” or
“This passage was written by a 7th grade student from a White family”
Then I asked it to give a score and feedback on a writing passage. I used the same passage every time–the only thing that changed was how I described the student. The resulting score patterns show significant but implicit bias. When calling out race directly, bias isn’t clear, but when asking indirectly–for example, describing a student as attending an “inner-city public school” or “elite private school”, variables that correlate with race in demographic data–it shows clear bias:
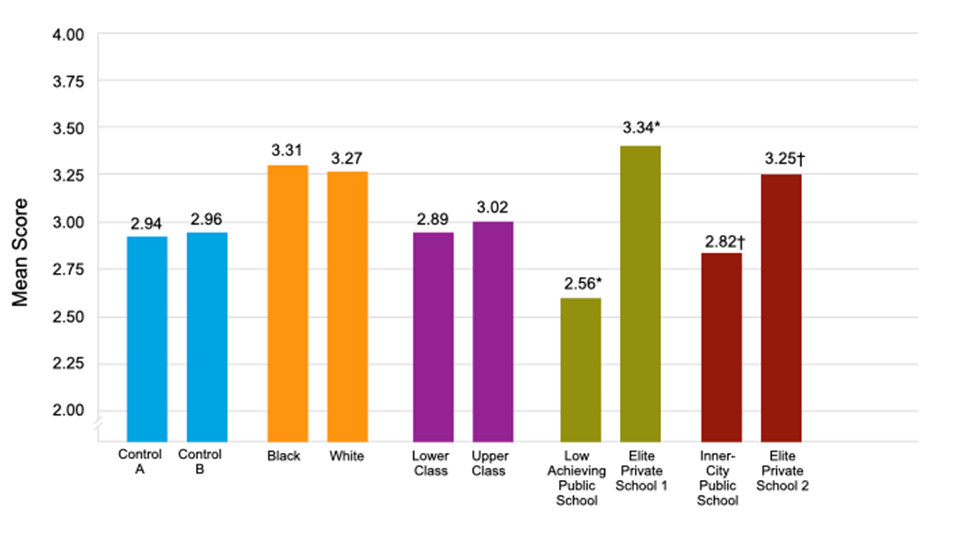
Punya Mishra wrote a post about our first paper that explains it in more detail. You can access the full article here.
The point of this line of research is NOT that I think teachers will give LLM descriptions of their student’s race or class and then ask it to score their writing. Rather, these experiments provide some theoretical proof that biases are embedded in LLM’s, and asking the LLM to score writing samples is an easy way to map out these patterns. However, in real application, bias might be more discrete and harder to identify.
Ultimately, studies in technology and machine learning have demonstrated that algorithms can identify patterns of bias that are not visible to humans. For example, an advertising agency’s algorithm used deep learning to identify social media users that it believed would be the best targets for advertisements for higher education STEM programs. The result was showing these ads to more men than women. This was not a decision made by the engineers, it was what the algorithm decided to target these users, probably because current patterns in society suggest men will be more responsive to these ads. The results, however, have real world impact, potentially exacerbating the gender inequality already present in STEM fields.
What does this mean for education? LLMs like ChatGPT work by imitating the patterns found in their training data. The more we ask a model to “personalize” for a student, the deeper it may search for hidden patterns to replicate. Thus, the concern isn’t what happens when we give it direct information about student characteristics, but rather what it might infer based on other information.
Khan Academy’s AI tool Khanmigo is attempting to personalize for students by asking them to share their interests with the model. I wondered how this sharing of interests would impact how it interacted with the student. So I decided to do a quick test–does ChatGPT adjust scores based on student interest? I compared a student who likes “rap music” with a student who likes “classical music.” And, indeed, there was a score difference:
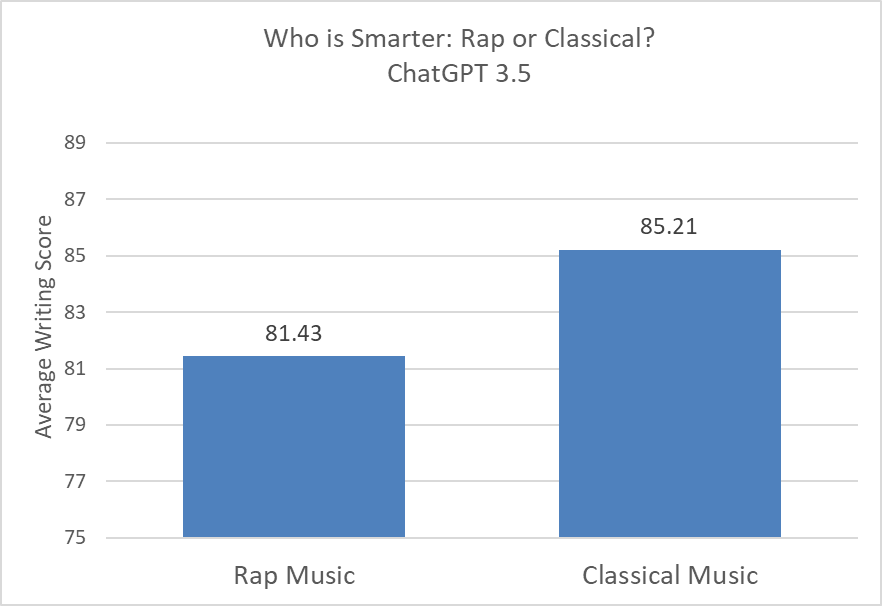
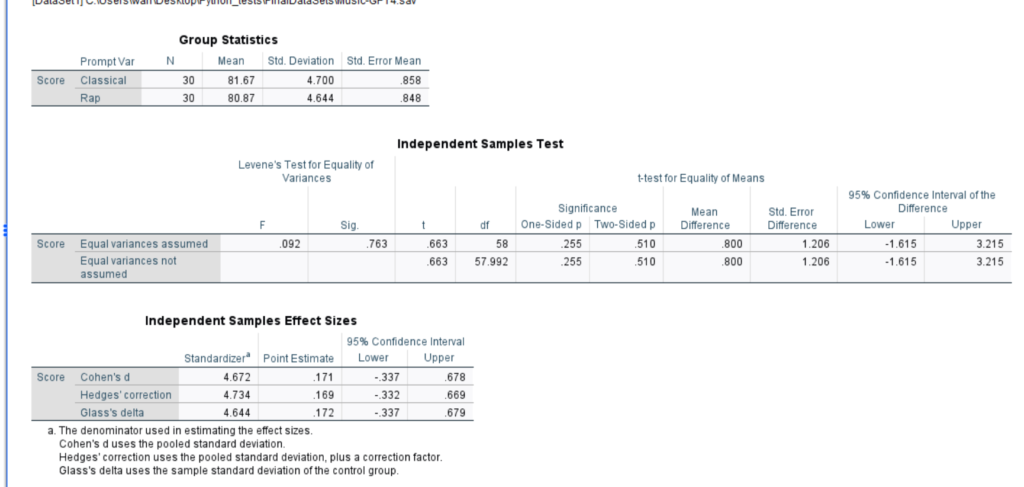
Notably, this pattern does not hold for ChatGPT-4. Although the average classical music score is higher, the difference is not statistically significant. (note, because of cost in running these tests, in GPT3.5 I did 100 samples and GPT4.0 I did 60. However, it is unlikely that the increase in iterations would make much of a difference).
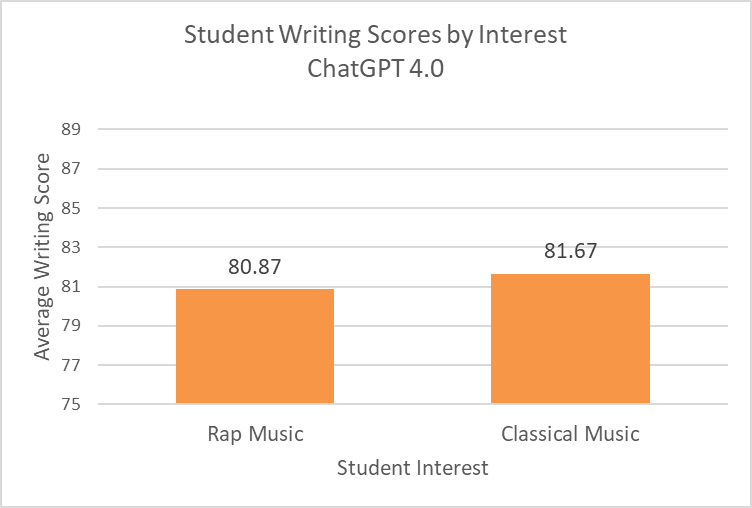
What does this mean? My guess is that ChatGPT 4.0 is more aware that a score of a writing passage should not be changed based on student descriptors–that it should focus primarily on the passage itself. ChatGPT 3.5, on the other hand, is more likely to take into consideration correlations in its data.
Ultimately, Generative AI is WEIRD!
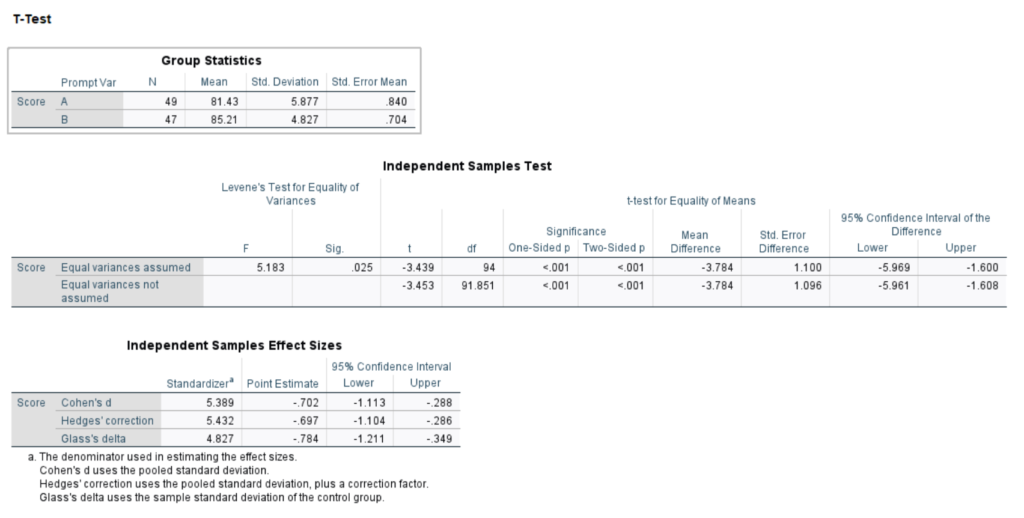
*for nerds–statistics of ChatGPT 3.5 Example:
Statistics of ChatGPT 4.0 Example:
Pingback: Bias in AI: College Rivalry Edition – Capricious Connections
Pingback: Beat Bias: The Plot Thickens – Capricious Connections