
While on a walk the other day, I was listening to a (rebroadcasted) episode of RadioLab:
During the episode, they discuss Benford’s Law–that in many contexts, there are more numbers that start with lower digits (1, 2, etc.) than higher digits (8, 9, etc.):
This law holds for river length, population growth, stock prices, and more. In fact, it has been used to identify fraud–and fake social media profiles.
Generative AI–like ChatGPT–has been taking up a lot of real estate in my head lately, and I wondered whether Benford’s Law could be demonstrated in ChatGPT. My theory was that the training data for ChatGPT had more numbers that started with 1 than 9, thus might be more accurate when using these numbers in addition problems.
So–I used Python to generate random addition problems. Each problem added two numbers–both that started with the same digit (1, 2, etc.) and was between 3 and 9 digits long*. For example: 1264295 + 1324 or 45234 + 42367342.
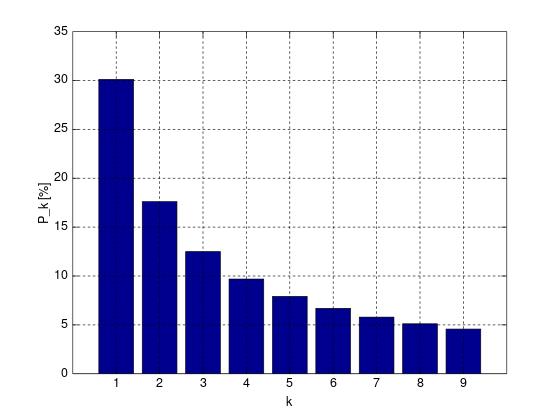
I created 2000 random addition problems, asked GPT3.5 to answer them, then calculated how frequently ChatGPT was correct. Ultimately, I found a modified Benford’s pattern:

Note, this likely would not work using GPT4, as it is more likely to realize it needs to calculate the answer instead of give a number based on correlations.
What does this mean? I’m not exactly sure. But it is, like much of what we have discovered about generative AI, weird.
*For nerds: To control for the case where numbers with higher first digits might simply be larger than those with lower first digits, in part of the data I created numbers beginning with digits 1-4 had between 4 and 9 digits, and first digits 5-9 and between 3 and 8 digits. Ultimately, a regression analysis indicated that the actual size of the numbers did not predict accuracy.
For nerdier nerds…leading digits of 5, 6, 7, 8, or 9 were significant predictors of accuracy in the answer (controlled for size of numbers). Digits for which the proportion correct were significantly different included 9 with all other digits, and 5 with digits 1-4 (based on Tukey’s HSD analysis).

For the nerdiest: You can access the Python script and the spreadsheet with the data here. Let me know if you notice anything else!
Pingback: Who Writes Better? Rap Fans or Classical Fans? – Capricious Connections
Pingback: Bias in AI: College Rivalry Edition – Capricious Connections