
GenAI is weird. It is not human, but it can sound like it. It is very confident in its errors but, when confronted, quick to apologize…and repeat the same errors again. It could be seen as a synthesis of the internet (good, bad, and ugly) but with human guardrails that attempt to fix the ugly stuff. It is implicitly biased. Attempts to improve models to not provide uniform results; some things get better, some things get worse. Working with it is incredibly useful, but also fraught with danger and risk. And no one fully understands it.
Because of this strangeness, appropriate and effective use requires an approach and way of thinking that is quite different from other ways we think and act in life. Developing critical use requires exploration, considering what it can and cannot do, pushing its limits. This is where creative exploration comes in–we engage in creative explorations by trying new things and reflecting on the results. We learn about GenAI by using it, taking an action, learning from the result, then acting again.
Punya Mishra is a great example of someone who plays with AI. He comes to know it through exploration, and you can find many examples of this on his blog. I have shared a couple of my explorations as well, including an investigation of Benford’s Law and writing bias of college rivalries.
A Picture is Worth 1000 Words
One I haven’t shared yet was based on an idea of Nicole Oster. I uploaded a picture of my cat:

I asked ChatGPT4 for 1000 words describing the picture. Here’s an excerpt of what I got:
In essence, this image encapsulates a snapshot of modern living, where pets are not just animals but family members. The cat, with its regal bearing and entrancing gaze, is clearly the monarch of its domain. The cactus scratching post, both functional and decorative, showcases the lengths pet owners go to ensure their pets’ comfort while maintaining a sense of style in their living spaces. The play of light and shadow, the minimalist background, and the captivating subjects all combine to create a visually delightful tableau.
Excerpt from ChatGPT4’s 1000 word Description
Then I started a new conversation, pasted the description and asked for an image that represents it.

Finally, I asked for a cartoon version:

This was just for fun, something to do while watching murder trials on YouTube. But I actually learned a fair amount about the type of language the LLM pulled on to describe the picture, the themes it was exploring, and what elements it found worthy of highlighting. It illustrated how a detailed description could result in a pretty good picture.
March Madness
Pictures of cats are all well and good, but the internet is already full of them. What if I could use an LLM to predict sport scores…or build a bracket? And finally win that family March Madness bracket trophy I’ve been coveting for years?
I could just directly ask it to predict scores…if I’m using GPT4 that pulls on the internet it might give me something like this:
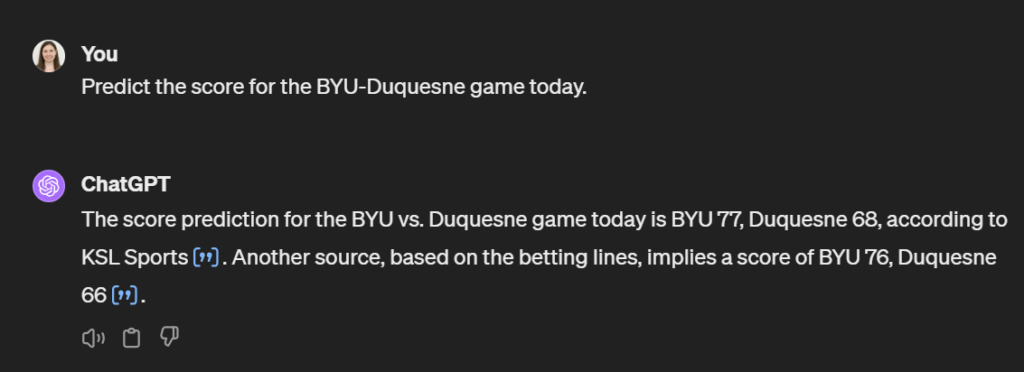
But what about games further along the bracket?
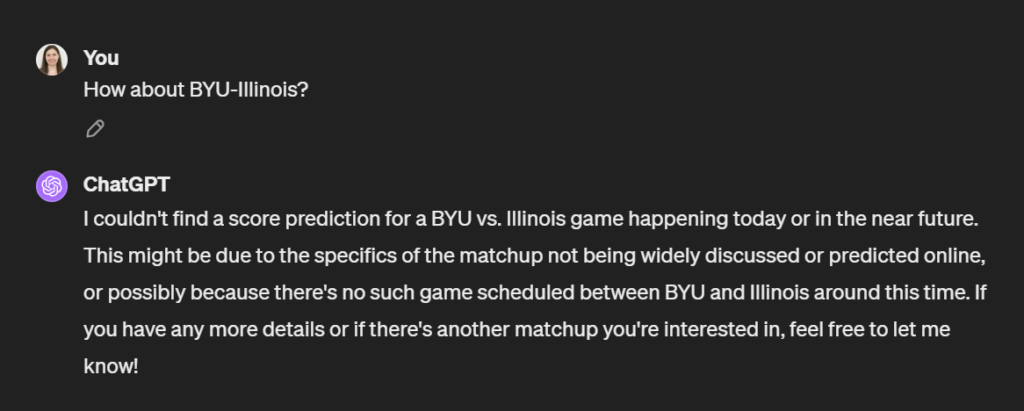
I could phrase it differently:

Not really that helpful.
But what if there is some pattern to the score it suggests…something that is more than just a “guess”, something that has some connection with actual odds? Rather than the calculations and analysis that many do as they create their brackets, I am curious about whether the language patterns (including any scores that were in the training data) might be predictive. And I wanted to draw on the whole implicit nature of LLMs, that they show patterns even when you don’t ask for them and they don’t mean to give them.
So, I asked GPT4 to help me write a Python script that would take my bracket, run each pair of teams through some function that resulted in a winner, then put it into the bracket for the next round. It gave me a nice program that actually worked the first time (that doesn’t always happen…), saving me the time of running potential match-ups one by one.
For the function to create the winner, I used this prompt: “Give me a pretend basketball score for {team1} vs. {team2}. Only give the score in the form of {team1}: {team2}: . Include no other text.”
I gave it the prompt 10 times then set the team that had won the most games of the set as the ultimate winner.
The first time I ran it, I was surprised that the winning team was almost always the higher seed…but then realized that it was simply giving a higher score to which ever team I mentioned first. This required a bit of an adjustment.
In Version 2, I alternated which team I listed first then chose the team with the highest average score (across the 10 iterations) as the winner. This version still often resulted in the higher seed winning, but not always–and there was less of a pattern. My final ChatGPT 3.5 bracket is here.
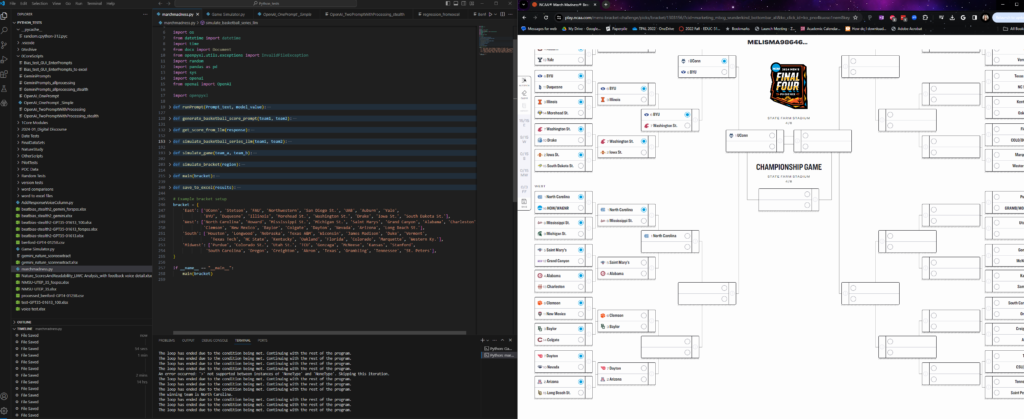
Since the code was ready to, I also ran it on Gemini. Here’s the final Gemini bracket. We’ll see which does best!
The fact that the highest average score was usually the higher seed–even though in half the iterations the other team was given a higher score because it was listed first–suggested there was something more than randomness.
These types of experiments help me explore the oddities and patterns of LLMs while knowing that these patterns are unlikely to hold across models and versions (something I have learned through exploration!). They help me observe the way it can work and think flexibly and critically about what they do and what I can do with them.
Stay tuned to see how the brackets do…and whether I finally win my family March Madness trophy!